Asynchronous programming model has become so popular these days that programmers use it without actually understanding it. This leads to confusions such as conflating concurrency with parallelism. What is asynchronous I/O exactly and how does it work under the hoods? In this post, we’re going to be answering these questions and then building a bare-bones event loop from scratch in C to demonstrate async I/O.
Models of programming
Programming model is an abstract concept that explains how the program is structured and how it will run when executed. In order to appreciate asynchronous programming model, we need to first talk about two other ways to structure programs.
Synchronous model
Synchronous model is the most simple one and, as the name implies, it runs tasks one at a time. Any task that is currently running must complete fully before another one can be scheduled. This means that future tasks need to wait for previous ones to be completed; hence, synchronous. This model is not well-suited for I/O-bound workloads, i.e. a program that initiates a lot of I/O requests.
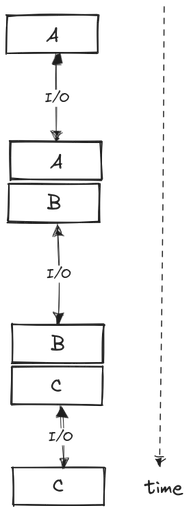
I/O is an abbreviation of input/output and it refers to any task that does not involve CPU computation. Examples include reading from a disk or writing data to some network. I/O tasks are orders of magnitude slower than CPU tasks. In synchronous, single-threaded programming model, the CPU becomes idle whenever an I/O task is initiated. Nothing else can be done until the completion of I/O. Therefore, to gain maximum performance, we need to model our programs such that the CPU is not sitting idle waiting for I/O most of the time.
Threaded model
Threaded model runs each task, or a bunch of tasks, on a separate thread of control which are managed by the OS. On a multi-threaded microchips, some number of these threads will run in parallel. This is great since the time needed to run multiple tasks is reduced significantly and the program is utilizing as much performance as available by the underlying hardware.
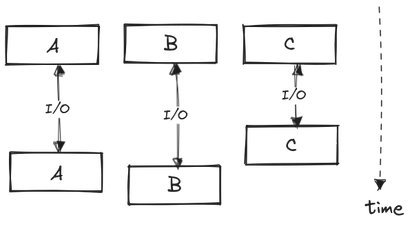
There are, however, two problems with the threaded model. First, each thread will still sit idle when an I/O request is initiated, and we lose CPU time that could be potentially used elsewhere. Second, multi-threaded models are hard to program and reason about. In single-threaded model, a future task has the guarantee that previous tasks are completed successfully. Since the order of task completion is arbitrary in multi-threaded programs, there is no such guarantee. To overcome this, we have to use concurrency constructs such as locks or shared memory, which are complex and error-prone.
Asynchronous model
Asynchronous model is the only paradigm that actually addresses the crux of the problem: blocking I/O. In this model, the tasks are interleaved such that minimum amount of time is spent waiting for I/O. So, say when a task A performs an I/O request, it yields control back to the program instead of blocking it. The program can now run other tasks freely. After some amount of time, the program will re-run the paused task A given that its I/O request is completed. This model is also sometimes referred to as cooperative multitasking.
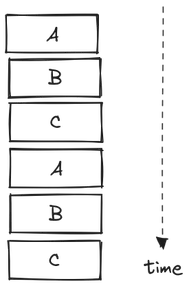

Asynchronous model is great because of its non-blocking nature, so that the program utilizes as much CPU time as possible. Also, this model is slightly easier to work with since it is single-threaded. Hence, you don’t have to deal with the complexities of cooperating multiple threads. Generally, asynchronous I/O model performs similar or better than its threaded counterpart.
epoll and friends
Programs that use a single thread to handle concurrent tasks asynchronously often use a pattern called an event loop. An event loop is exactly what it says: a continuous loop that waits for events. It watches a queue of tasks, where each task generates some event (such as I/O completion). The event loop by default is in a waiting state. Whenever an event of interest is produced by some task, the event loop processes that task. And then repeat.
But how can we write a program that can notify us about I/O completion? Turns out that it cannot be done without the help of the operating system. Thus, the OS kernel provides a bunch of system calls that serve as I/O event notification facility. A modern version of this in Linux is epoll, which we’ll use in the next section to implement our event loop. epoll is a set of system calls that allows monitoring of multiple network sockets to see if I/O is possible on any of them. Similar APIs exist in other operating systems as well. Windows has IOCP and macOS has kqueue.
In modern programming languages, the implementation of the event loop is hidden behind an abstraction. This is generally achieved by making blocking I/O calls, such as reading from a file, non-blocking by default and accept a function that will be called when the I/O call completes. Anyone who has written asynchronous JavaScript will be be familiar with this callback function concept.
Curious where epoll and friends are used? Here’s a brief list:
- Google Chrome uses libevent which is a wrapper library around epoll and friends
- Node.js uses libuv which is also a wrapper library around epoll and friends
- Go programming language uses epoll for network I/O
- Rust’s
tokioruntime uses epoll
Building the loop
That’s neat but now lets build our own event loop from scratch. We will be using C programming language so that we can strip away abstractions and really see how it all works under the hoods.
The following code example creates a UDP server and tells the Node.js event loop to listen for message events. Whenever some data is sent to the server, the event loop runs the callback function, which simply logs the received data in this case.
import dgram from 'node:dgram';
const server = dgram.createSocket('udp4');
server.on('message', (msg, rinfo) => {
console.log(`server got: ${msg} from ${rinfo.address}:${rinfo.port}`);
});
server.bind(41234);We will build an event loop that will expose a similar API to register a callback function for message event on a UDP server. To make things a little more interesting, we will echo the message back to the client instead of just logging it. Full source code can be found on GitHub.
Interface
Lets define the public API first.
Server *createServer(int port);
void on(Server *server, EventType event, void (*callback)(Request *));
void startServer(Server *server);These functions should be self-explanatory by their names. Note the on function is used to register a callback function on some event type, quite similar to Node.js example. The callback gives a Request object as function argument that has the message and client’s details.
struct Request {
struct sockaddr client_addr;
socklen_t addr_size;
int server_sockfd;
char *msg;
};EventType is an enum that defines all event types. We just have one event type currently, that is message event.
enum EventType { EventTypeMessage }Server struct contains an array of callback functions, one slot for each type of event.
struct Server {
int port;
int sockfd;
void (*cb_array[EVENT_TYPES_LEN]) (Request *);
};Implementation
Since this is not a socket programming 101 post, I will skip over creating the server socket. It is on GitHub if you’re curious.
Lets start with callback register function called on, which is really simple. Surprisingly, it is just one line of code: store callback function in the server’s callback array.
void on(Server *server, EventType event, void (*callback)(Request *)) {
server->cb_array[event] = callback;
}startServer is where interesting stuff happens. It is here that you’ll find the famous event loop. Before that, we create a new epoll instance via epoll_create system call. We then add our server’s socket to the interest list of epoll via epoll_ctl system call. Note the EPOLLIN flag which tells epoll that we’re interested in readiness of only read operations. Read the friendly manual for more information.
void startServer(Server *server) {
int epollfd = epoll_create1(0);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = server->sockfd;
epoll_ctl(epollfd, EPOLL_CTL_ADD, server->sockfd, &ev);
...
}Finally, we have our event loop. We first call epoll_wait which blocks until our server socket is ready for read operations. It returns the number of ready events and stores those events in events array. So, we check each one in the for loop and check if its a read event on the server’s socket (which it will be on every case as we only have our server’s socket in the epoll interest list). We then read the message from client, create an instance of Request and pass it to the callback function we stored earlier for message event.
void startServer(Server *server) {
...
// The event loop
while (1) {
int nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
// Check if we can read on server's socket
if (events[i].events & EPOLLIN && events[i].data.fd == sock) {
struct sockaddr client_addr;
socklen_t addr_size = sizeof(client_addr);
char buf[BUF_SIZE];
memset(buf, 0, BUF_SIZE);
recvfrom(sock, buf, BUF_SIZE, 0, &client_addr, &addr_size);
// Run the callback
Request req = {client_addr, addr_size, sock, buf};
server->cb_array[EventTypeMessage](&req);
}
}
}
}Demo
Let’s take our fresh event loop for a spin. We create a new server on port 41234, register our handler function that echoes back the message and start the server. See how similar the following C code looks to the Node.js example above.
void handleMessage(Request *req) {
sendto(req->server_sockfd, req->msg, BUF_SIZE, 0,
&req->client_addr, req->addr_size);
}
int main() {
Server *s = createServer(41234);
on(s, EventTypeMessage, handleMessage);
startServer(s);
}Compile the application and start the server. It should be listening for datagrams on specified port.
$ make
$ ./demo
Listening on port 41234Here I use netcat CLI tool to send UDP messages to our server.
$ nc -u 127.0.0.1 41234
Hey
Hey
Echo server
Echo serverAlthough our event loop only polls for a single event type, it can extended as required. Nonetheless, it serves as a basis for how event loops are generally implemented under the covers. And that’s a wrap.
References
https://unixism.net/2019/04/linux-applications-performance-introduction/
https://man7.org/linux/man-pages/man7/epoll.7.html
https://github.com/binjamil/eventloop
Further reading
https://unixism.net/loti/async_intro.html
https://krondo.com/an-introduction-to-asynchronous-programming-and-twisted/
https://copyconstruct.medium.com/the-method-to-epolls-madness-d9d2d6378642
https://idea.popcount.org/2016-11-01-a-brief-history-of-select2/
https://darkcoding.net/software/epoll-the-api-that-powers-the-modern-internet/